J'ai décidé de faire porter mon TIPE (Travail d'Intérêt Personnel Encadré, à réaliser pendant les classes préparatoires scientifiques) sur les réseaux de neurones artificiels, car je suis attiré par l'intelligence artificielle, et cette facette de l'IA est particulièrement intéressante et offre un bon potentiel pour un TIPE.
Il s'inscrit dans le thème 2003-2004 "Objets, structures, formes et matériaux (reconnaissance, représentation et analyse)" dans la perspective générale "Les Technologies et les Sciences mises au service du Développement Durable".
Le contenu complet du TIPE est désormais disponible en téléchargement ici (dossier avec code source principal, transparents, programmes).
Plan du dossier
1. Notions générales1.1. Présentation des réseaux de neurones artificiels
1.1.1. Le neurone artificiel
1.1.2. Les fonctions de transfert
1.1.3. L'apprentissage
1.1.4. Les principaux types de réseaux
1.2. Notions d'optimisation
1.2.1. Optimisation contrainte et non contrainte
1.2.2. Méthodes itératives d'optimisation
2. Apprentissage supervisé des réseaux non bouclés
2.1. L'approximation
2.1.1. Approximateurs universels
2.1.2. Approximateurs parcimonieux
2.2. L'apprentissage : un problème d'optimisation
2.2.1. La fonction d'erreur
2.2.2. L'algorithme de rétropropagation du gradient
2.2.3. Localité de l'optimisation et améliorations
2.2.4. Vitesse de convergence et améliorations
3. Applications et Réalisations
3.1. Reconnaissance de forme
3.1.1. Principe général
3.1.2. Fonctionnement
3.1.3. Résultats
3.2. Prévision de température
3.2.1. Réalisation d'un capteur
3.2.2. Exploitation du capteur
3.2.3. Réalisation d'un programme de régression et de prévision
3.2.4. Résultats
3.3. Applications de la prévision de température
3.3.1. Régulation de chauffage neuro-floue
3.3.2. Prévision des pics d'ozone
A. Bibliographie & Remerciements
B. Code source commenté
Contenu complet du TIPE en téléchargement (dossier et logiciels)
| Dossier (PDF) |
Dossier (483Ko) Fiche synoptique (120 Ko) |
|---|---|
| Soutenance (PDF) |
Transparents et exposé (169 Ko) |
| Programmes |
Reconnaissance de formes (270 Ko) Régression et prévision de température (372 Ko) |
| Contacts |
Cyril ROUSSILLON mail : contact@cteknologies.fr URL : crteknologies.free.fr |
Présentation des réseaux neuronaux
Les réseaux de neurones artificiels, ou réseaux neuromimétiques, sont des modèles inspirés du fonctionnement du cerveau animal, dans le but de voir surgir des propriétés analogues au système biologique. Ces modèles en prennent en compte quelques grands principes :- parallélisme : les neurones sont des entités réalisant une fonction très simples, mais très fortement interconnectées ce qui rend le traitement du signal massivement parallèle.
- poids synaptiques : les connections entre neurones ont des poids variables, ce qui rends les neurones plus ou moins influents sur d'autres neurones.
- apprentissage : ces coefficients synaptiques sont modifiables lors de l'apprentissage pour faire réaliser au réseau la fonction désirée.
Le neurone artificiel
Le neurone artificiel général
Le neurone formel de Mc Culloch et PittsLa notion de neurone formel a été pour la première fois avancée par Mc Culloch et Pitts en 1943. Ils ont prouvé que pour des poids judicieusement choisis ce modèle offrait la puissance d'une machine de Turing universelle.
Nous ne nous étendrons pas sur ce modèle, cas particulier du neurone général, qui présentait la particularité d'être binaire, c'est à dire qu'il était soit actif, soit non actif.
Le neurone artificiel général
Chaque neurone possède plusieurs entrées, à chacune d'entre elles on affecte un poids, et une sortie. A chaque entrée peuvent être connectées plusieurs sorties d'autres neurones. La sortie est calculée à partir des entrées et des poids synaptiques : une fonction d'entrée calcule le potentiel du neurone, celle-ci est très souvent la somme pondérée (par son coefficient) des entrées augmentée d'un seuil. Une fonction de transfert génére alors la sortie grâce à ce potentiel. Cette fonction de transfert est très importante, et détermine le fonctionnement du neurone et du réseau. Elle peu prendre de nombreuses formes, peut être linéaire, binaire, saturée ou sigmoïdale.
Modélisation générale d'un neurone :

Le neurone se décompose en deux parties :
- évaluation de la stimulation reçue : fonction d'entrée
- évaluation de l'état de sa sortie (son état interne) : fonction de transfert (ou fonction d'activation)
L'entrée fixée à 1 de poids b est facultative et représente le seuil (ou biais). On peut ajouter cette entrée à un réseau pour tous les seuils des neurones.
Les fonctions de transfert
Voici un tableau récapitulatif de différents types de fonctions de transfert, les plus utilisées, avec leurs équations mathématiques et leurs dérivées, dont nous verrons les applications dans différents types de réseaux dans la partie suivante.| Catégorie |
|
||||||||||||
| Seuil |
|
||||||||||||
| Linéaire |
|
||||||||||||
| Sigmoïde |
|







Il est bien sûr possible de discrétiser fonctions (afin de stocker des entiers). On peut également appliquer un coefficient additif à la fonction, et simuler un seuil comme vu plus haut avec une entrée supplémentaire fixe au réseau.
Il faut cependant être prudent avec les fonctions sigmoïdes, car pour des entrées grandes la fonction exponentielle peut provoquer un débordement (overflow), et il peut être nécessaire de vérifier que l'entrée n'est pas trop grande avant d'appliquer l'équation générale.
L'apprentissage
On peut distinguer deux principaux types d'apprentissages :- supervisé : on fournit au réseau le couple (entrée, sortie) et on modifie les poids en fonction de l'erreur entre la sortie désirée et la sortie obtenue.
- non supervisé : le réseau doit détecter des points communs aux exemples présentés, et modifier les poids afin de fournir la même sortie pour des entrées aux caractéristiques proches.
La règle de Hebb
Méthode d'apprentissage la plus ancienne (1949), elle est inspirée de la biologie. Le principe est de renforcer les connections entre deux neurones lorsque ceux-ci sont actifs simultanément. Cette règle peut être classée comme apprentissage non supervisé, ou supervisé car on sait calculer directement les poids correspondant à l'apprentissage d'un certains nombres d'exemples.
La règle du delta (ou règle de Widrow-Hoff)
Son but est de faire évoluer le réseau vers le minimum de sa fonction d'erreur (erreur commise sur l'ensemble des exemples). Elle est utilisée dans le modèle de l'adaline (ADAptive LINear Element). L'apprentissage est réalisé par itération (les poids sont modifiés après chaque exemple présenté), et on obtient le poids à l'instant t+1 par la formule : W(t+1) = W(t) + n.(T - O).E si W est le poids, T la sortie théorique et O la sortie réelle, E l'entrée et n un coefficient d'apprentissage (entre 0 et 1) que l'on peut diminuer au cours de l'apprentissage.
C'est en fait un cas particulier de l'algorithme de rétropropagation du gradient.
La rétropropagation du gradient (backpropagation)
Cette règle, utilisée par les réseaux multicouches, consiste simplement en une descente de gradient, qui est une méthode d'optimisation universelle. On cherche à minimiser une fonction d'énergie d'erreur (qui représente l'erreur entre la sortie désirée et la sortie obtenue), en suivant les lignes de plus grande pente. Une fonction d'erreur rapportée à une dimension peut se représenter ainsi :

On peut se représenter la descente de gradient comme une bille que l'on poserait sur la courbe, et qui descendrait logiquement la pente (le gradient est la dérivée en plusieurs dimensions et représente donc la pente de la courbe).
La rétropropagation de base utilise le gradient de l'erreur globale (obtenue avec tous les exemples), mais a l'inconvénient de s'arrêter dans le premier minimum local rencontré. Diverses améliorations ont été apportées :
- La descente stochastique : comme dans la règle de Widrow et Hoff, on minimise itérativement l'erreur due à chaque exemple. Les apprentissages de chaque exemple s'influençant les uns les autres, cela permet de passer sur des petits minima locaux. Une présentation aléatoire des exemples donne généralement de meilleurs résultats.
- La descente avec inertie : on introduit un moment d'inertie (terme de momentum), qui correspond dans notre image de la bille, à l'inertie qu'elle acquiert en descendant la courbe : son élan lui permettra de ne pas s'arrêter dans le premier minimum local rencontré.
- Le gradient conjugué, la QuickProp, la RPROP sont d'autres améliorations de cet algorithme.
Principaux types de réseaux
Mémoires auto-associatives et Réseaux de Hopfield
Dans la désignation mémoire associative, le terme mémoire fait référence à la fonction de stockage de ces réseaux, et le terme associative au mode d'adressage, puisque qu'il faut fournir de l'information au réseau pour obtenir celle qui est mémorisée, c'est une mémoire adressable par son contenu.Avec les mémoires auto-associatives, il faut fournir une partie de l'information pour obtenir l'information stockée (par exemple : partie du visage pour obtenir le visage en entier).
Structure
Chaque neurone est relié à tous les autres, et à toutes les entrées. La fonction de transfert est habituellement l'identité, et l'évaluation peut se faire de manière synchrone (toutes les unités évoluent en même temps) ou asynchrone (les éléments du réseaux évoluent les uns après les autres).
Apprentissage
Il est de type supervisé, c'est-à-dire que la base d'apprentissage est constituée de couples de vecteurs entrée et sortie associés, et est basé sur la règle de Hebb.
Applications
Les applications des ces mémoires sont essentiellement la reconstruction de signaux et leur reconnaissance.
Réseau de Hopfield
Le modèle de Hopfield est une mémoire auto-associative dont la réponse des neurones est asynchrone, et dont les neurones ont pour fonction de transfert la fonction signe, c'est-à-dire dont la réponse est binaire.
Les fondements mathématiques de ces réseaux sont très bien compris, et il est possible réaliser l'apprentissage par un calcul direct à partir des exemples à mémoriser grâce à la règle de Hebb généralisée.
Mémoires hétéro-associatives et Cartes topologiques de Kohonen
Avec les mémoires hétéro-associatives, on fournit une information au réseau et celui-ci rend une information différente (par exemple : visage donne le nom).Structure
Chaque neurone est relié à toutes les entrées, mais les neurones ne sont pas reliés entre eux. La fonction de transfert est linéaire.
Apprentissage
Diverses méthodes peuvent être utilisées, comme la règle de Hebb ou la règle du delta.
Applications
Les mémoires à apprentissage supervisé sont principalement utilisées pour la mémorisation et la reconnaissance de formes (associer le nom d'une lettre à l'image de la lettre par exemple). Les réseaux à apprentissage non supervisés sont en revanche utilisés pour des fonctions de classification et d'agrégation (clustering).
Les cartes auto-organisatrices de Kohonen
Kohonen s'est inspiré de la topologie de certaines zones du cortex qui présentent la même organisation que les capteurs sensoriels : des zones proches correspondent à des neurones proches dans le cortex. Tous les neurones sont interconnectés, mais seuls les neurones proches ont de l'influence, selon une une fonction DOG (Difference of Gaussian) en forme de "chapeau mexicain" : les neurones les plus proches sont excitateurs, ceux un peu plus éloignés inhibiteur et les plus éloignés ont une influence nulle. La fonction d'entrée est de type sigmoïde, et le réseau présente la particularité de n'avoir qu'un seul neurone actif à la fois. Il réalise une tâche de classification : des entrées aux caractéristiques proches donnent une même sortie.
Les réseaux multicouches (non bouclés)
Les MLP (multi-layer perceptron), ou réseaux à couches, forment la très grande majorité des réseaux. Ils sont intemporels (réseaux statiques et non dynamiques).Structure
Les neurones sont organisés en couches : chaque neurone est connecté à toutes les sorties des neurones de la couche précédente, et nourrit de sa sortie tous les neurones de la couche suivante (ces réseaux sont d'ailleurs qualifiés de feedforward en anglais : "nourrit devant"). Pour la première couche ses entrées sont l'entrée du réseau. D'ailleurs une couche est souvent rajoutée pour constituer les entrées, appelée couche d'entrée, mais elle n'en est pas une puisqu'elle ne réalise aucun traitement.
Les fonctions d'entrée et de transfert sont les mêmes pour les neurones d'une même couche, mais peuvent différer selon la couche. Ainsi la fonction de transfert de la couche de sortie est généralement l'identité.
Apprentissage
Les réseaux multicouches utilisent la règle de rétropropagation du gradient décrite plus haut. Les fonctions de transferts doivent donc être différentiables, c'est pourquoi on utilise des fonctions sigmoïdes, qui est une approximation infiniment dérivable de la fonction à seuil de Heaviside.
Applications
Les applications des réseaux non bouclés sont très diverses et étendues. Elles vont de la reconnaissance de motifs, à la modélisation en passant par l'apprentissage de comportements ou de jeux.
Réalisations
Je présente maintenant les réseaux que j'ai programmés, disponibles en téléchargement . Le code source des principales parties se trouve en annexe du dossier, également disponible en téléchargement ici.Premier logiciel de reconnaissance de formes
Principe
Mon réseau ne comporte qu'une seule couche, avec autant de neurones que de formes à reconnaître, avec autant d'entrées que de pixels des formes et donnant en sortie la probabilité (%) qu'il s'agisse de la bonne forme. Il s'agit d'un apprentissage supervisé, si la forme reconnue est la bonne on renforce l'apprentissage selon l'écart avec la seconde forme reconnue (renforcement), si le réseau s'est trompé il renforce les valeurs de la forme qui aurait due être reconnue et les baisse pour la forme reconnue (correction d'erreur).Résultats
Mon ANN parvient à reconnaître parfaitement les 26 lettres minuscules en une quarantaine d'apprentissages, en reconnaissant la lettre en moyenne à 80%, avec une moyenne d'écart de 50% avec les autres lettres, 20% avec la lettre arrivant en seconde position, et un écart minimum entre la lettre reconnue et la seconde tournant autour de quelques %.On arrive à atteindre un écart moyen avec le second de 80% et un écart minimum de plus de 70% au bout d'environ 300 apprentissages, apprentissage automatique bien sûr :).
Il parvient également à identifier les lettres parmi trois polices différentes avec un écart minimum supérieur à 5% après quelques 1500 apprentissages, c'est à dire qu'on lui présente un 'a' d'une police ou d'une autre il reconnaitra un 'a'.
Utilisation du programme

Reconnaissance
On commence par charger dans "classes (ANN)" les formes qui consitueront les types de formes à reconnaître (fichiers bitmap .bmp qui doivent tous avoir les mêmes dimensions, possibilité d'ouvrir plusieurs fichiers en une fois).A chaque clic sur sur une forme, celle-ci se dessine et une reconnaissance s'effectue automatiquement, les résultats pour chaque classe s'affichant à gauche (probabilité en % pour qu'il s'agisse de la bonne forme). La classe reconnue s'affiche en rouge et se focalise, et la seconde classe reconnue s'affiche en bleu foncé.
On peut charger de même dans "formes" les formes que l'on souhaite, qui seront identifiées par rapport aux classes.
Apprentissage
Après chaque reconnaissance, on peut choisir "apprendre", après avoir éventuellement sélectionné la bonne classe dans la liste déroulante sous le bouton, que le réseau se soit trompé ou non .Apprentissage automatique
Le programme comporte une fonction d'apprentissage automatique.type :
- sequentiel : chaque forme est reconnue dans l'ordre, si le réseau s'est trompé on procède à un apprentissage puis on passe au suivant dans tous les cas.
- suiv. si prec. : chaque forme est reconnue dans l'ordre, mais si le réseau s'est trompé on procède à un apprentissage puis on vérifie que les formes précédentes sont toujours correctement reconnues. Ce mode est légèrement plus long mais donne des résultats un peu meilleurs.
- justes : l'apprentissage s'arrête quand toutes les formes sont identifiées sans erreur.
- ecart 2° > : l'apprentissage s'arrête quand toutes les formes sont identifiées sans erreur et l'écart minimum entre une forme reconnue et la seconde est supérieur à la valeur précisées.
inclure formes : précise si les formes chargées dans "formes" doivent être apprises. Il faut dans ce cas que leur nombre soit multiple du nombre de classes, et chaque forme est supposée comme appartenant à la classe correspondante dans "classes (ANN)". Les formes sont alors prises en compte pour tous les paramètres et dans l'évalutation de l'apprentissage.
n apprentissages, n reconnaissances : précise le nombre d'apprentissages et de reconnaissances qui ont été effectuées lors du dernier apprentissage automatique.
Si l'apprentissage ne se termine pas, par exemple parce que vous avez chargé des formes identiques, ou exigé un écart avec le second trop important, vous pouvez appuyer sur le bouton "stop" pour arrêter immédiatement l'apprentissage automatique.
Evaluation apprentissage
Après chaque apprentissage, une évaluation est effectuée, affichant plusieurs paramètres :trouvé moy. : pourcentage moyen de reconnaissance des formes
ecart moy. : écart moyen entre la forme reconnue et les autres
ecart 2° moy. : écart moyen entre la forme reconnue et la seconde
ecart 2° min : écart minimum entre une forme reconnue et la seconde
Les paramètres les plus importants sont les deux derniers, et surtout le dernier.
Si toutes les valeurs sont à 0, cela signifie qu'au moins une forme n'a pas été correctement reconnue.
Autres
intervalle init [0,1] +- : précise l'intervalle d'initialisation des poids du réseau.continuite min ]0,2] : fait en sorte que la différence entre deux poids de pixels voisins ne dépasse pas la valeur spécifiée. Cette option est prévue pour de ne pas rendre un pixel trop décisif afin d'optimiser les capacités de généralisation du réseau, mais elle s'est révélée peu efficace.
Régression et prévision de température
Présentation
Le programme utilise un réseau multicouches et la méthode d'apprentissage de rétropropagation du gradient, ainsi que diverses améliorations. Le réseau est entièrement paramétrable, et le programme possède deux modes : régression et prévision.Il donne de bons résultats puisqu'il parvient à approcher diverses fonctions avec une bonne précision, et pour la prévision de température à une échéance de trois heures à une erreur inférieure à 3 ou 4 °C dans les cas extrêmes, et inférieure à 1 ou 2 °C la plupart du temps.
Tous les fondements théoriques et les détails techniques se trouvent dans le dossier, disponible en téléchargement ici.
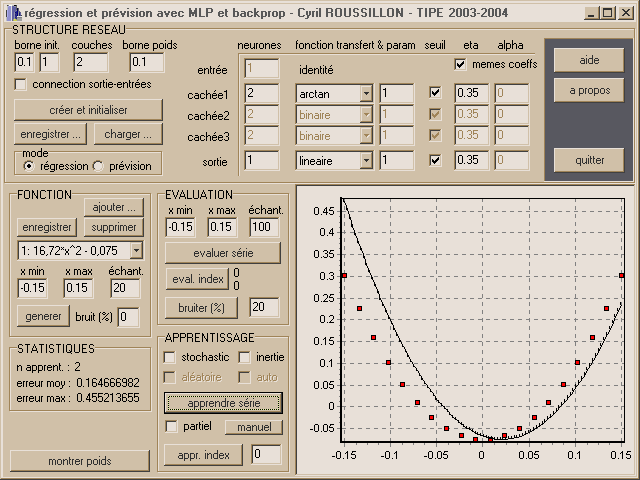
Utilisation
Structure du réseauOn a la possibilité de totalement paramétrer le réseau, avec un maximum de trois couches cachées, ce qui laisse un large éventail de possibilités.
Pour chaque couche de neurone, on peut choisir :
- le nombre de neurones de la couche
- la fonction de transfert utilisée par les neurones de la couche ainsi que son paramètre (voir 1.1.2).
- le fait que les neurones de la couche possèdent un seuil, ajustable par l'apprentissage
- les coefficients d'apprentissage qui seront utilisés pour les neurones de cette couche
On peut également préciser si on veut qu'il existe une connexion entre les entrées et les neurones de la couche de sortie, ce qui peut permettre de traiter la partie linéaire d'un problème, ainsi qu'une borne qui délimite les valeurs possibles d'initialisation des poids lors de la création du réseau.
Il est aussi possible d'enregistrer sur le disque dur un réseau satisfaisant, puis de le recharger ultérieurement.
Enfin, il existe deux modes :
- régression : le réseau tente, quand on lui fournit une valeur d'abscisse, de fournir la valeur associée (le réseau comporte alors une seule entrée, modélisée par le nombre de neurones de la pseudo couche d'entrée).
- prévision : on fournit au réseau un certain nombre de valeurs consécutives de la fonction (le nombre d'entrées), et il tente de prédire la valeur suivante. Cette prévision peut être étendue à une plus grande échéance (précisée dans "Durée max prev." de la zone "Prévision"), en réutilisant des valeurs déjà prédites en entrée.
Fonction
On peut choisir ici dans la liste déroulante la fonction de son choix à utiliser pour l'apprentissage du réseau en régression ou prévision. Celle-ci est stockée avec son intervalle d'utilisation et le nombre d'échantillonnages à utiliser lors de son tracé, échantillonnages qui constituent la base d'exemples d'apprentissage du réseau. De plus, afin de simuler des données expérimentales, du bruit peut être ajouté à la fonction lors de son tracé.
Afin de pouvoir utiliser n'importe quelle fonction, j'ai écrit un interpréteur d'expressions arithmétiques. Le code source se trouve en annexe B : l'expression est analysée puis convertie en un arbre, qui permet le calcul de la fonction en n'importe quel point.
On peut donc ajouter une fonction, la supprimer de la liste, ou simplement modifier son intervalle d'utilisation (bouton "enregistrer"). Il est également possible d'obtenir les données à partir d'un fichier, sous le format décrit dans le paragraphe sur le capteur de température (3.2.2).
Evaluation
On peut dans cette zone définir l'intervalle d'évaluation du réseau, qui peut être avantageusement plus grand que celui d'utilisation de la fonction (et donc d'apprentissage), pour visualiser le comportement du réseau dans un domaine ou il n'a subit aucun apprentissage.
On peut ensuite évaluer le réseau sur tout l'intervalle d'évaluation ("evaluer série"), ou un seulement un indice précis de l'échantillonnage de la fonction en mode régression. S'affichent alors la valeur attendue et la valeur rendue.
Il est également possible de bruiter les poids du réseau pour dégrader l'apprentissage, afin de pouvoir examiner comment le réseau converge de nouveau.
Statistiques
Lors de chaque évaluation du réseau, l'erreur qu'il commet par rapport à la fonction est calculée : il s'agit de l'erreur relative (par rapport à l'amplitude de la fonction sur son intervalle d'utilisation) moyenne, ainsi que de l'erreur relative maximale.
Est également affiché le nombre d'apprentissages qu'à subit le réseau depuis son initialisation.
Apprentissage
Plusieurs algorithmes d'apprentissage sont disponibles :
- Gradient simple : Si aucune case à cocher n'est cochée, correspond à l'algorithme de base. Chaque exemple est soumis au réseau, l'erreur est calculée, rétropropagée, et les corrections sont stockées. Une fois que tous les exemples ont été traités, on applique la moyenne des corrections au réseau.
- Gradient stochastique : Ici les corrections sont aussitôt appliquées après chaque exemple soumis. On peut également présenter les exemples dans un ordre aléatoire, ce qui peut améliorer la convergence mais aussi augmenter l'instabilité.
- Gradient inertie : Un terme est ajouté à la correction, constitué du produit d'un coefficient alpha et de la correction précédente. Les coefficients eta et alpha peuvent être calculés automatiquement par l'algorithme présenté en 2.2.3.
- Manuel : Pour un réseau à une couche cachée de deux neurones, trace les applications partielles, permettant de localiser manuellement chaque minimum.
On peut alors effectuer l'apprentissage sur toute la base d'apprentissage, ou seulement sur un indice (l'indice est le même que celui de la zone Evaluation). On peut également n'utiliser qu'un exemple sur deux pour l'apprentissage, mais tous pour calculer l'erreur, ceci afin de vérifier la capacité de généralisation.
Il est finalement possible de visualiser en temps réel les poids du réseau, en cliquant sur le bouton "montrer poids".